How we evaluate and improve grade-level alignment in MagicSchool

We took a deeper look at grade-level alignment across MagicSchool. Here’s what we tested, what we found, and how we’re improving.
Editor's note: This post was authored by Chris Rohlfs, Staff Data Scientist, with Keanon O'Keefe, Senior Technical Product Manager. Chris and Keanon are both members of the Trust, Safety, and Quality team at MagicSchool.
Recently, an independent third party published findings suggesting that MagicSchool-generated content met grade-level expectations about two-thirds of the time overall, with lower accuracy in science content.
We take analyses like this seriously. They’re an opportunity to look more closely, test more rigorously, and improve.
Grade-level alignment is foundational in K–12 education. When AI generates content for students, the vocabulary, sentence structure, and conceptual complexity need to match where students are. Responsible AI in schools requires consistent performance at scale across classrooms and use cases.
Why does grade-level alignment matter?
Instructional effectiveness depends on readability. A passage written at the 7th grade level doesn’t help a 3rd grader, and it may even create friction instead of support. Teachers use tools like MagicSchool to strengthen standards-aligned instruction, and grade-level calibration is a core part of their work.
Lower grade bands need even more precision. For students in grades K–3, the margin for error is small. Vocabulary load, sentence length, and concept density carry more weight. A tool that works well for high school but falls short in early elementary isn’t meeting the needs of the full classroom.
There’s also an important distinction between demo performance and performance at scale. A system might generate a well-calibrated paragraph in one instance and produce a different result the next time the same prompt is used. Looking at a small number of outputs doesn’t reflect how the system behaves overall. Consistency becomes clear with repetition and volume.
The importance of independent testing
We believe independent evaluation makes AI tools better. Looking at actual outputs across subjects, grade bands, and prompt types helps surface issues that internal review alone can miss.
It’s also important to understand how generative AI systems behave. No two runs are identical. A single output is one data point, not the full picture. To see how a system is performing, you have to look across multiple runs of the same prompt and how results vary over time.
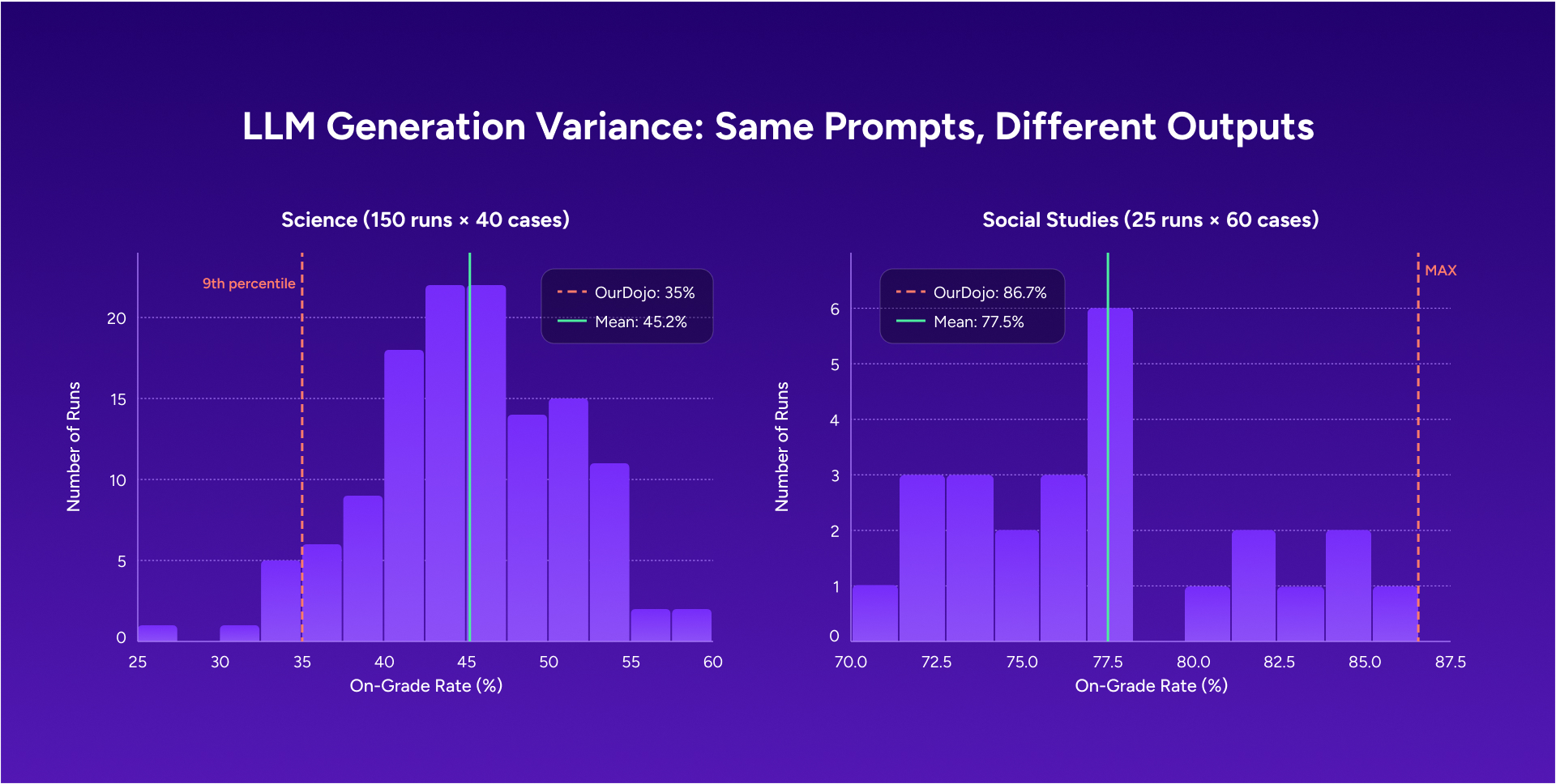
Smaller analyses can be noisy and sometimes over-index on outliers. They can also surface issues worth looking into. Expanding the analysis gave us a clearer view of what was inconsistent, what was typical, and where we needed to improve.
What we did
The independent analysis evaluated a single tool, the teacher-facing Informational Texts Generator, across 100 prompts targeting 3rd grade content. Those prompts were split between science (40 cases) and social studies (60 cases). It’s a useful starting point, and we used it as one.
From there, we expanded the evaluation significantly:
- ~12,000 total evaluations, compared to 100 in the original study
- 9 tools evaluated, including both teacher- and student-facing experiences like Raina, AI Learning Assistant, AI Tutor, and Content Creator
- Multiple runs per prompt to account for variability and understand how outputs change over time
- Three prompt approaches per case, including baseline replication and improved prompting
We focused on outputs using the same Learning Commons Readability Rubric referenced in the original analysis. Alongside that, MagicSchool runs an ongoing AI Safety Loop that looks at additional dimensions like vocabulary, sentence structure, factual accuracy, tone, writing quality, cohesion, completeness, and inclusion.
Testing across subjects, grade bands, tools, and prompt structures, with multiple runs for each condition, gives us a clearer view of how the system is performing.
What we learned
The original findings were directionally correct. Grade-level variability exists in MagicSchool-generated content, and science at lower grade levels is the most challenging case.
At the same time, the scope and magnitude were shaped by the sample. The tool evaluated, the teacher-facing Informational Texts generator, is one of the lower-performing tools in our expanded data set. It was also tested with a single prompt approach. When we ran the same 100 cases across all 9 tools, a more complete picture started to come through.
The original analysis reported an overall accuracy rate of 66 percent, with science at 35 percent and social studies at 87 percent. In our expanded evaluation, other student-facing tools performed at higher on-grade rates, ranging from 70 percent to 100 percent. When outputs went above the target grade level, they were usually one grade band higher. That still matters, but it looks different from the level of misalignment the headline number suggests. Larger gaps were uncommon.
Science content at lower grade bands is still the most challenging area for calibration. Domain-specific vocabulary in NGSS-aligned content adds a level of complexity that other subjects don’t carry.
The Informational Text Generator, especially for grades K–3, is where we have the most room to improve and where we’ve focused our work.
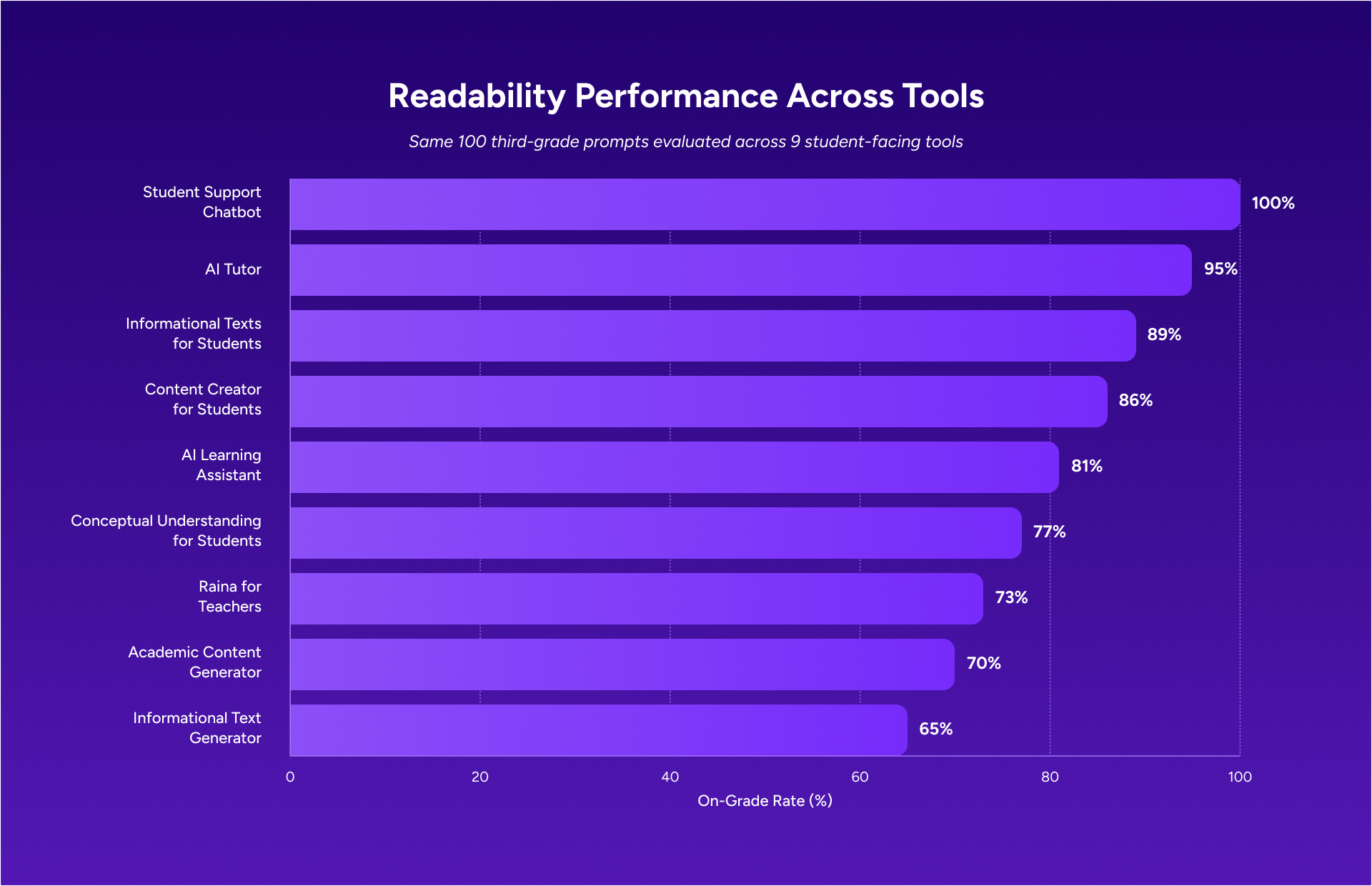
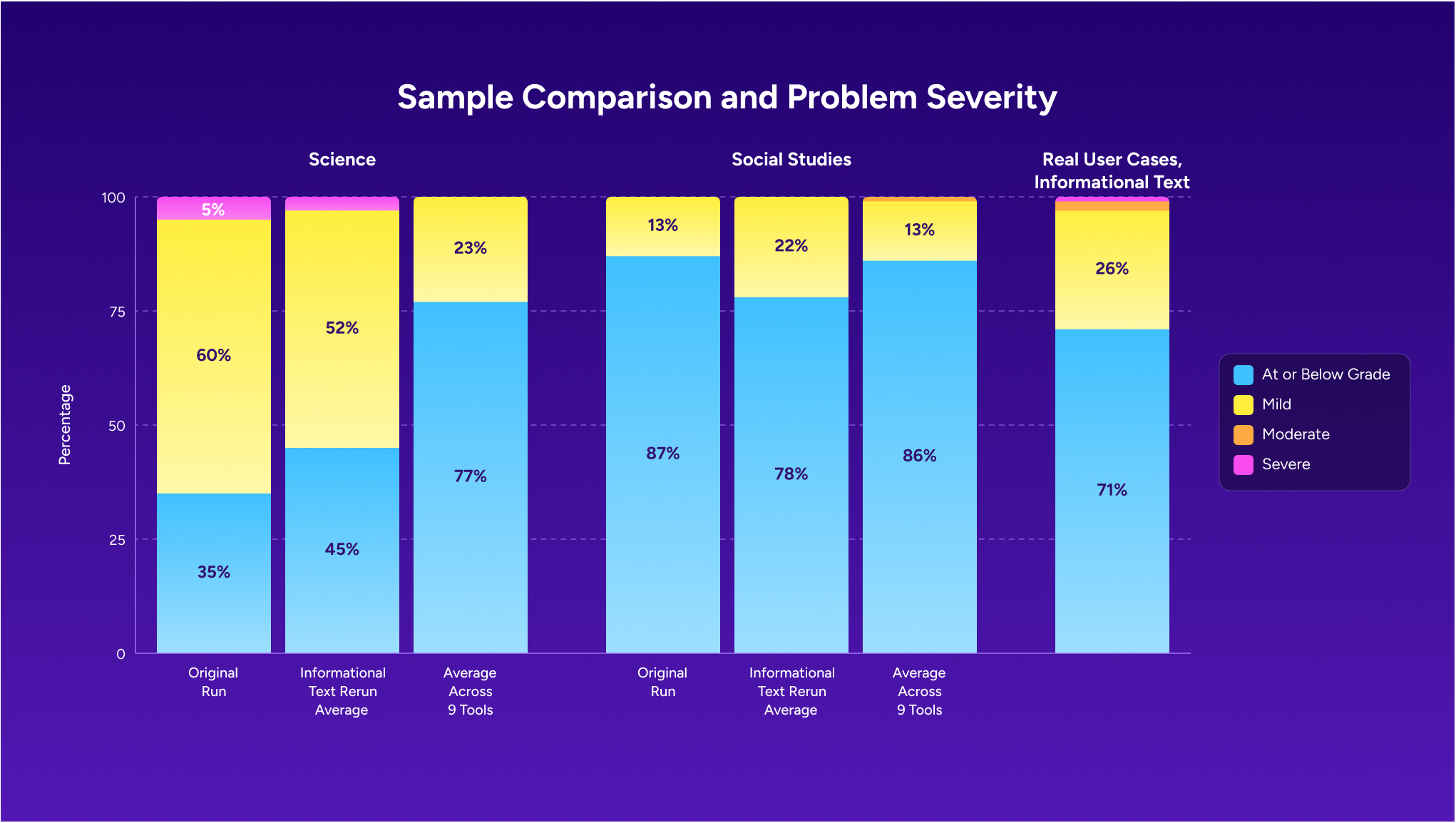
What we improved
Our review led directly to product changes. We added structured grade-level calibration guidance to both our Student and Teacher Global System Instructions (GSI), with clear targets by grade band:
- Grades K–2: 8–10 words per sentence, with a preference for single-syllable vocabulary
- Grades 3–5: 12–15 words per sentence, with limits on multisyllabic words
- Grades 6–8: 18–20 words per sentence
- Grades 9–12: Standard academic prose
These guidelines apply to student-facing content like passages, worksheets, and assessments. They’re separate from how we communicate with teachers.
Tools that showed the lowest performance received targeted prompt updates and were tested again to confirm improvement before changes were rolled out.
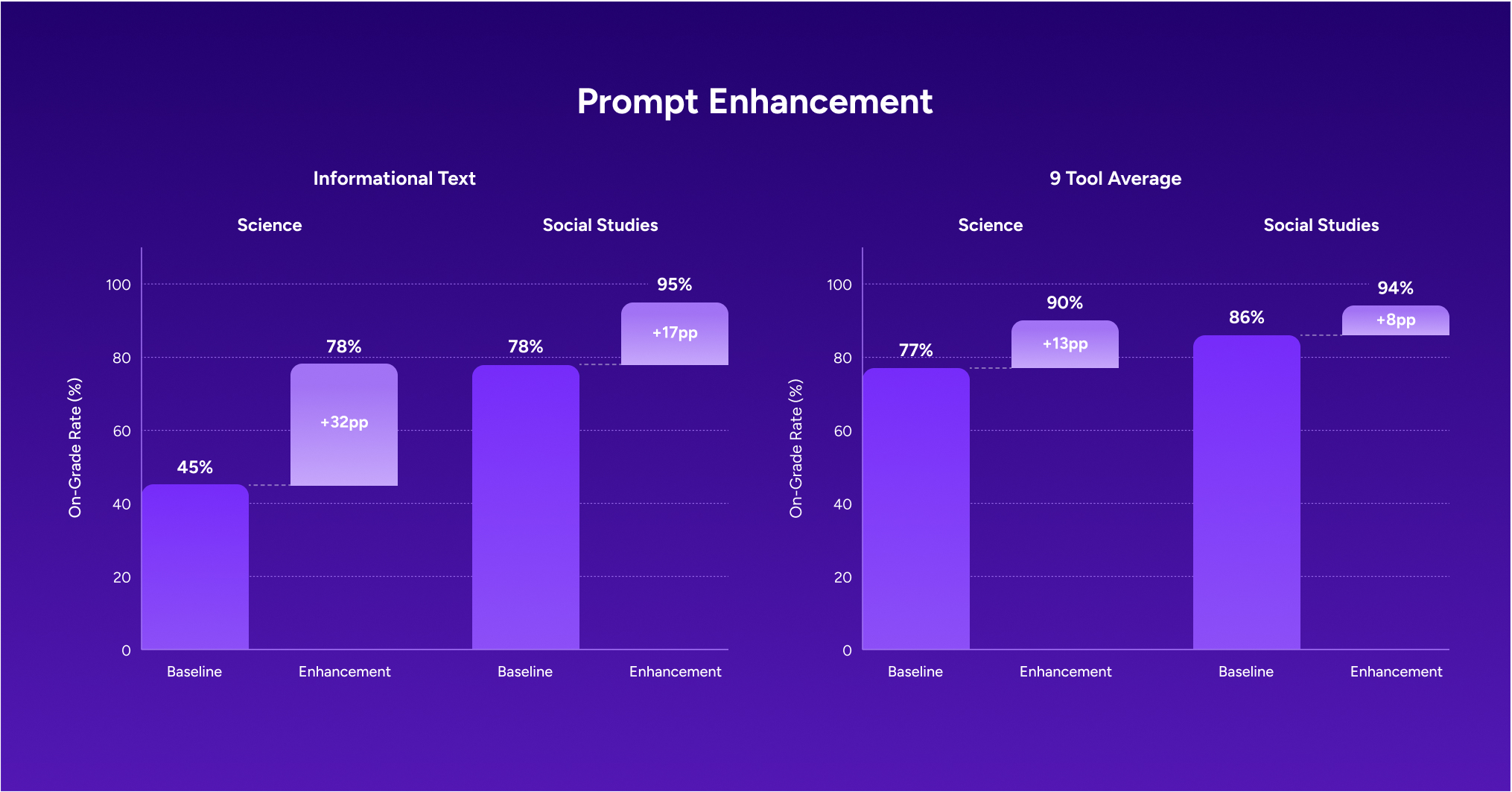
Our commitment moving forward
Our work doesn’t stop here. Grade-level calibration takes ongoing evaluation as models evolve, as we add new tools, and as we learn more about how prompt structure and subject area shape outputs. We’ll continue to run task-level evaluations across meaningful sample sizes as a standard part of how we build.
Districts also need visibility into how this work happens. When findings come up, whether through external analysis or our own review, we share what we learned and what we changed. We believe that level of transparency matters for MagicSchool and for how AI tools in education are evaluated and improved more broadly.












